Tyler Tries Unblocking the Event Loop
I’ve been ramping up on Node.js for my new team at Supabase, and I’ve learned the first rule of Node.js club: Don’t block the event loop.

I’m not going to get into the details of how the Node.js event loop works. Instead, I’ll walk through my experience debugging an issue where a library was blocking it.
My favorite resources to learn about the event loop:
We made a change to enable OpenTelemetry using the open source npm libraries @opentelemetry/*. After deploying this change, our max CPU spiked to 100%. By the time I came online, a discussion was already underway with various hypotheses about the cause.
Coincidentally, I recently read a blog post, Introducing Next-Generating Flamegraph Visualization in Node.js, and this seemed like the perfect use case for CPU profiling.
This isn’t my first time using flamegraphs. If you’ve read my blog post on Tyler Tries Web Development, I wrote about my experience with memray, a Python memory profiler. I linked some good resources there about what they are and how to read them.
Here is how I set up our app for profiling:
➜ git clone https://github.com/supabase/storage.git
➜ cd storage
➜ cp .env.sample .env
➜ npm add -D @platformatic/flame
➜ npm install
➜ npm run infra:start
➜ npx flame run --manual dist/start/server.jsI then ran a k6 script to generate some load on our app in a separate terminal:
➜ node src/test/k6/run-benchmark.cjsOnce the benchmark was over, I hit CTRL+C to stop the profiling and exit. This produced a CPU profile: cpu-profile-2026-03-20T15-59-05-224Z.pb. To create the flamegraph I ran:
➜ npx flame generate cpu-profile-2026-03-04T16-04-45-113ZThis produces an HTML and markdown file. Here is what the flamegraph looked like:
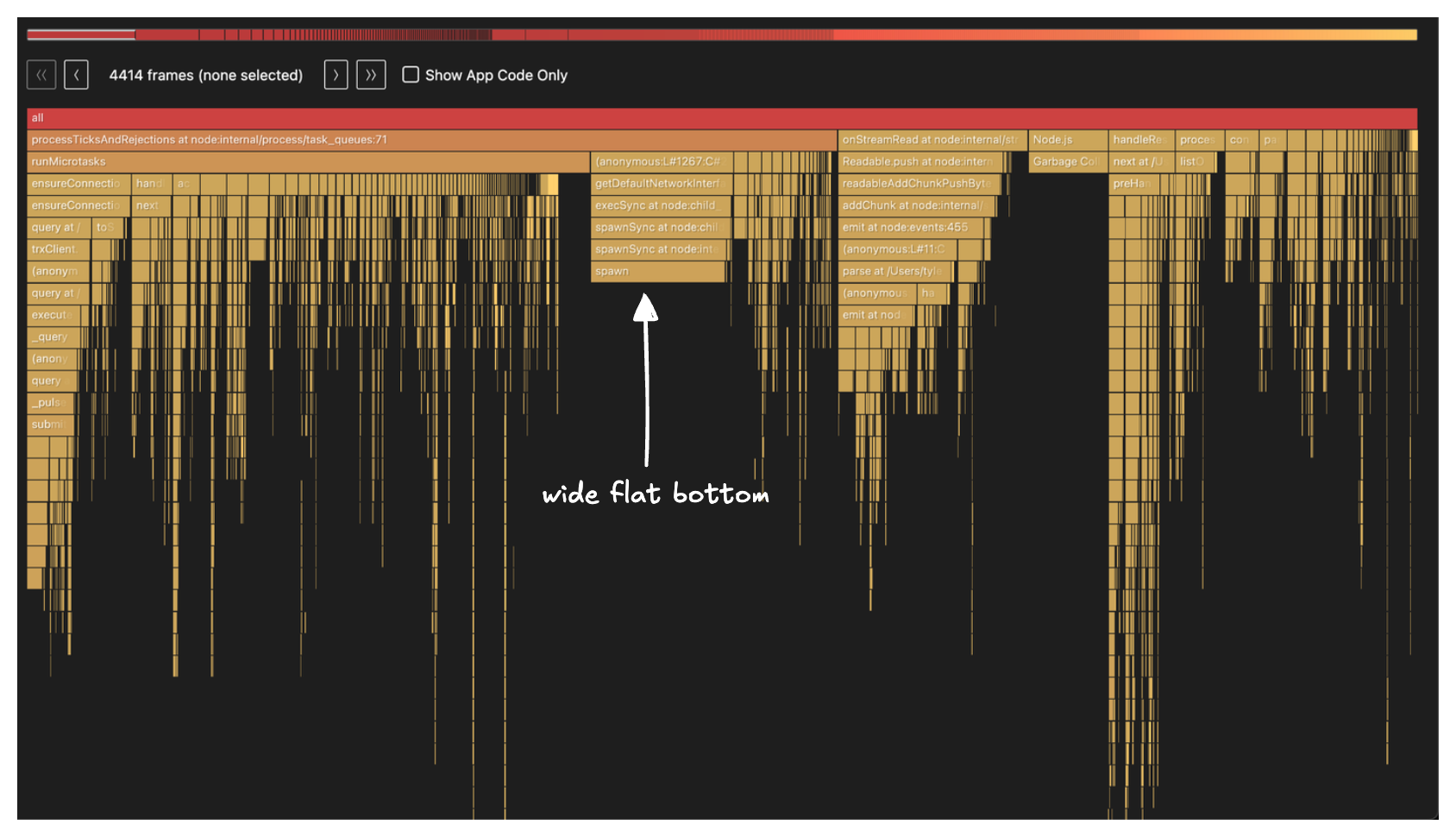
My main mental model when looking at flamegraphs is to look for the widest bottom of the flame. With this in mind, the stack frame labeled spawn caught my eye:
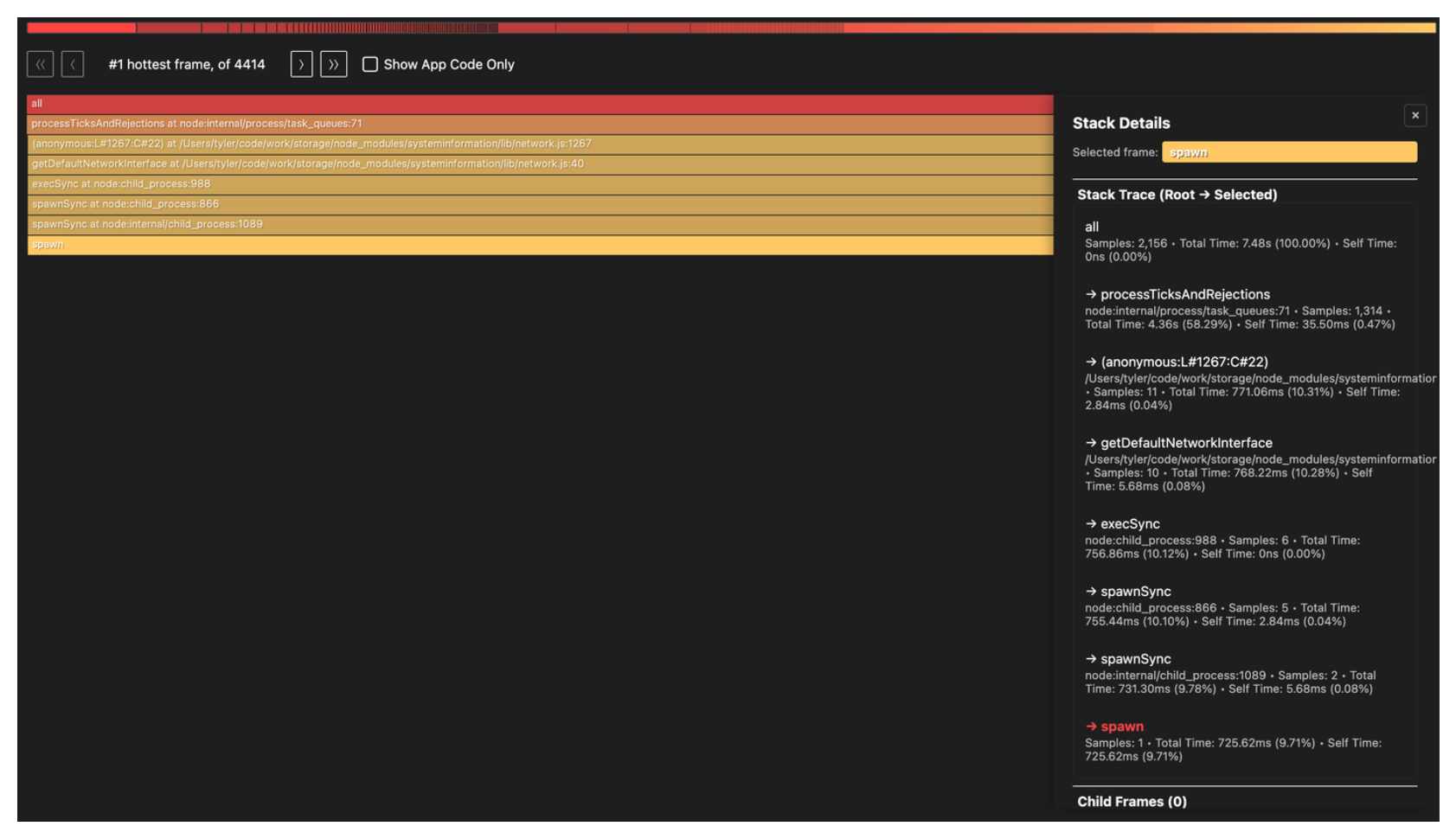
Going down the call stack, spawn is being called from getDefaultNetworkInterface() in node_modules/systeminformation/lib/network.js and it gets there via execSync(). Remember, the first rule of Node.js club is don’t block the event loop. Yet, here we have a synchronous call.
Another nice benefit of the flame tool is the markdown report it generates which confirms our interpretation of the flamegraph:
It’s clear that spawn is the main culprit, accounting for 10.3% of total CPU samples.
Unfortunately, the flamegraph doesn’t show the full call path and stops at node_modules/systeminformation/lib/network.js so we have to do some grepping:
➜ rg "systeminformation/lib/network" -u -l
node_modules/@opentelemetry/host-metrics/build/src/stats/si.js.map
node_modules/@opentelemetry/host-metrics/build/src/stats/si.jsObject.defineProperty(exports, "__esModule", { value: true });
exports.getNetworkData = void 0;
// Import from the network file directly as bundlers trigger the 'osx-temperature-sensor' import in the systeminformation/lib/cpu.js,
// resulting in the following warning: "Can't resolve 'osx-temperature-sensor'"
// See https://github.com/open-telemetry/opentelemetry-js-contrib/pull/2071
const network_1 = require("systeminformation/lib/network");
function getNetworkData() {
return new Promise(resolve => {
(0, network_1.networkStats)()
.then(resolve)
.catch(() => {
resolve([]);
});
});
}
exports.getNetworkData = getNetworkData;This confirms @opentelemetry/host-metrics is what’s calling into the systeminformation/lib/network module. This makes sense given our recent change to add OpenTelemetry. Now we just need to find where in our app we use it:
➜ rg "@opentelemetry/host-metrics" -l
package.json
package-lock.json
src/internal/monitoring/otel-metrics.tsHere is a condensed view of src/internal/monitoring/otel-metrics.ts:
import { HostMetrics } from '@opentelemetry/host-metrics'
// Initialize host metrics for Node.js runtime metrics
const hostMetrics = new HostMetrics({
meterProvider,
name: 'storage-api-host-metrics',
})
hostMetrics.start()We found it! This is what the full call path ends up looking like:
src/internal/monitoring/otel-metrics.ts:235
└─ hostMetrics.start()
└─ @opentelemetry/host-metrics → _createMetrics()
└─ registers a batchObservableCallback
└─ getNetworkData() [si.js:25]
└─ networkStats() [systeminformation/lib/network.js]
└─ getDefaultNetworkInterface()
└─ execSync → spawnSync → spawnThe fix we did for now was a simple one liner to emit the network metrics group:
const hostMetrics = new HostMetrics({
meterProvider,
name: 'storage-api-host-metrics',
+ metricGroups: ['system.cpu', 'system.memory', 'process.cpu', 'process.memory'],
})A long term fix is changing the systeminformation module itself to see if it can be made async.
There is an open PR titled: Use asynchronous operations everywhere to avoid blocking the main thread
but it was opened in 2024-11-22 with the last activity on 2025-03-05 so it doesn’t look like this will get merged anytime soon.
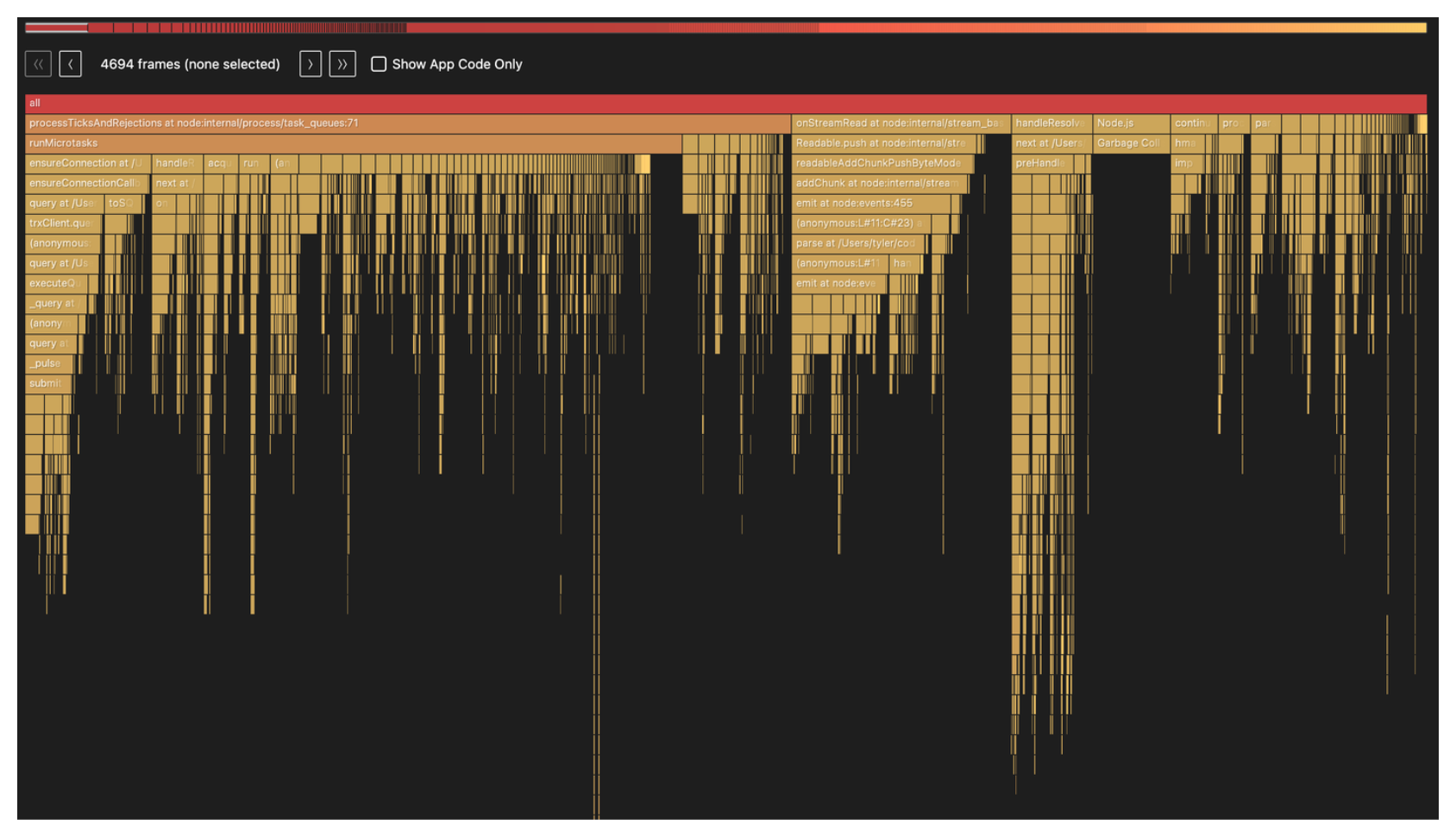
Here is a new flamegraph with the change:
Now for my favorite part, the event loop p99 latency across each of our app instances after we rolled out the fix:
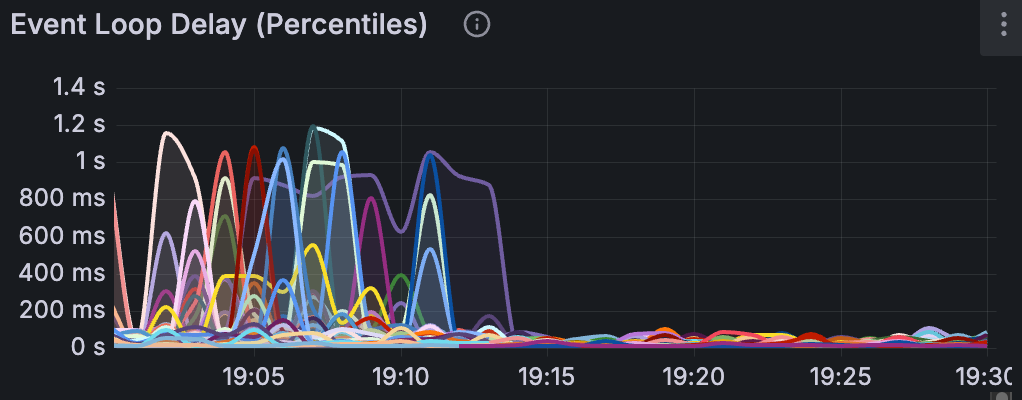
Event loop latency measures how long a callback has to wait before the event loop picks it up. When the event loop is blocked by synchronous work, that wait time grows, meaning every request queued behind it is delayed.
We saw consistent spikes to ~1s and you can infer when the deployment took place based on the nosedive in the charts.
So a reminder, don’t block the event loop.